반응형

Google Colaboratory, 줄여서 Google Colab(코랩)은 구글이 제공하는 클라우드 기반의 파이썬 개발 환경입니다.
특히 딥러닝·머신러닝·데이터 분석에 특화되어 있으며, 별도의 설치 없이 웹 브라우저만 있으면 바로 코드를 작성하고 실행할 수 있는 Jupyter Notebook 환경입니다.
왜 사용하는가?
- 개인 PC의 성능 한계를 극복할 수 있음 (무료 GPU 지원)
- 소프트웨어 설치 없이 바로 개발 가능 (딥러닝 프레임워크 사전 설치됨)
- 코드 공유 및 협업이 쉬움 (Google Drive와 통합)
- 학습 및 연구, 프로토타입 제작에 최적화
장점은 무엇인가?
| 항목 | 장점 |
| 접근성 | 웹 브라우저에서 바로 사용 가능 |
| 하드웨어 자원 | 무료로 GPU, TPU 제공(Tesla T4, P100 등) |
| 저장소 연동 | Google Drive와 연동해 파일 저장 및 불러오기 가능 |
| 딥러닝 지원 | TensorFlow, PyTorch, OpenCV 등 미리 설치되어 있음 |
| 협업 기능 | 다른 사람과 실시간으로 노트북 공유, 공동 편집 가능 |
| 버전 관리 | Github와 연동해 프로젝트 버전 관리 가능 |
그래서 어디에 쓰이는가?
- 딥러닝 모델 개발 및 학습 (TensorFlow, PyTorch)
- 머신러닝 실습 및 튜토리얼 공유
- 데이터 분석 및 시각화 (Pandas, Matplotlib, Seaborn 등)
- Kaggle, AI 경진대회 제출용 코드 테스트
- 연구용 논문 코드 재현
- 코드 리뷰 및 강의 자료 제작
사용법 (한 번에 끝내는 핵심 가이드)
1. 설치
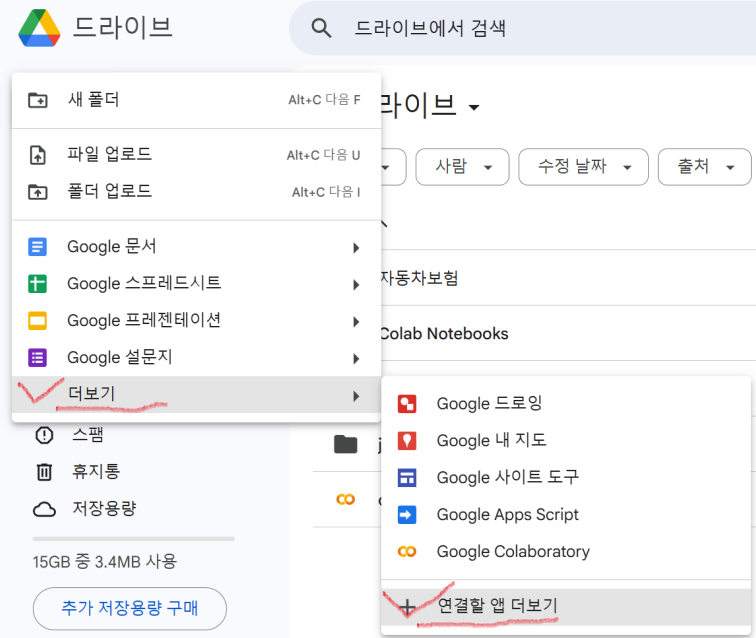
구글 드라이브에 들어갑니다.
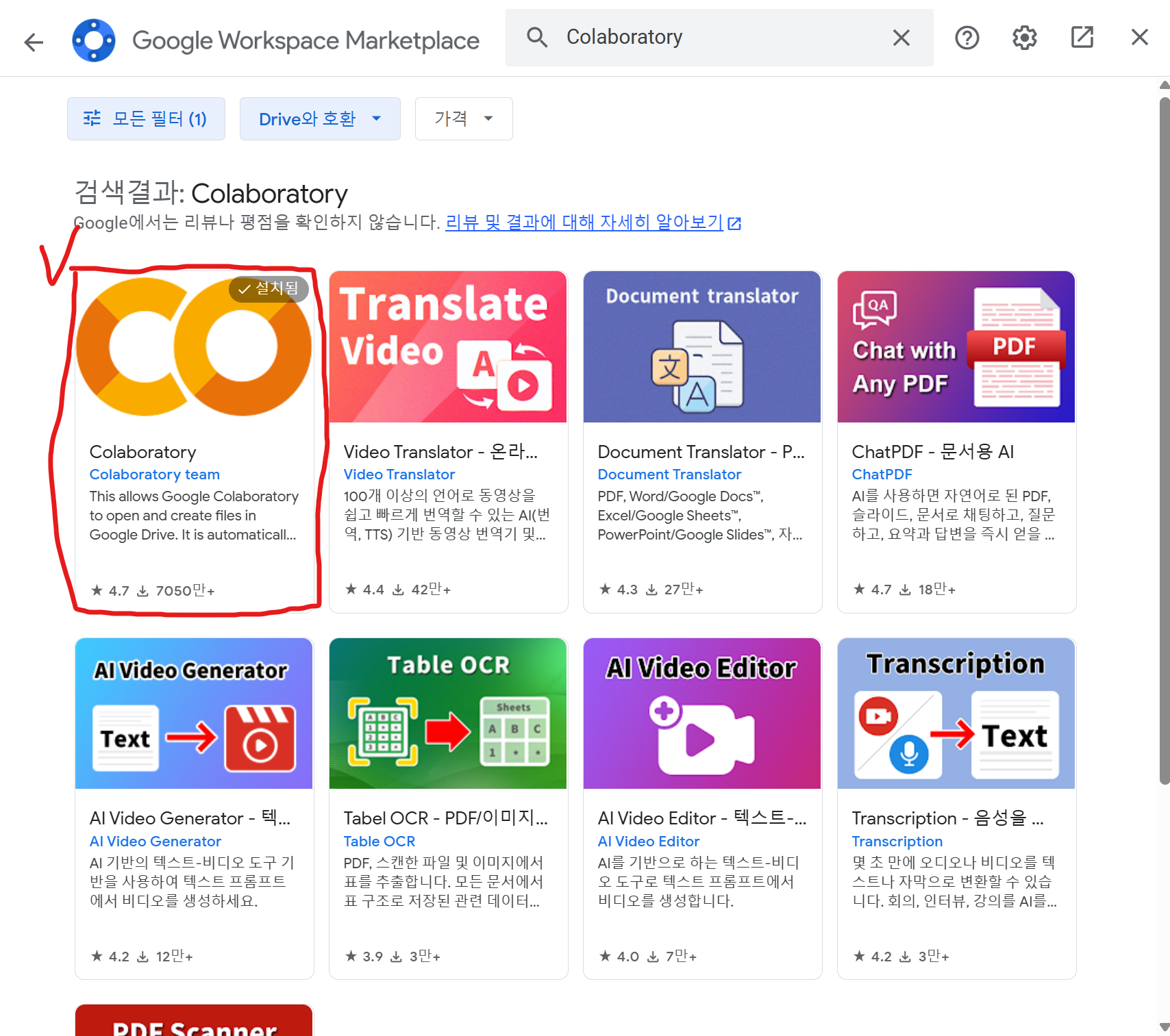
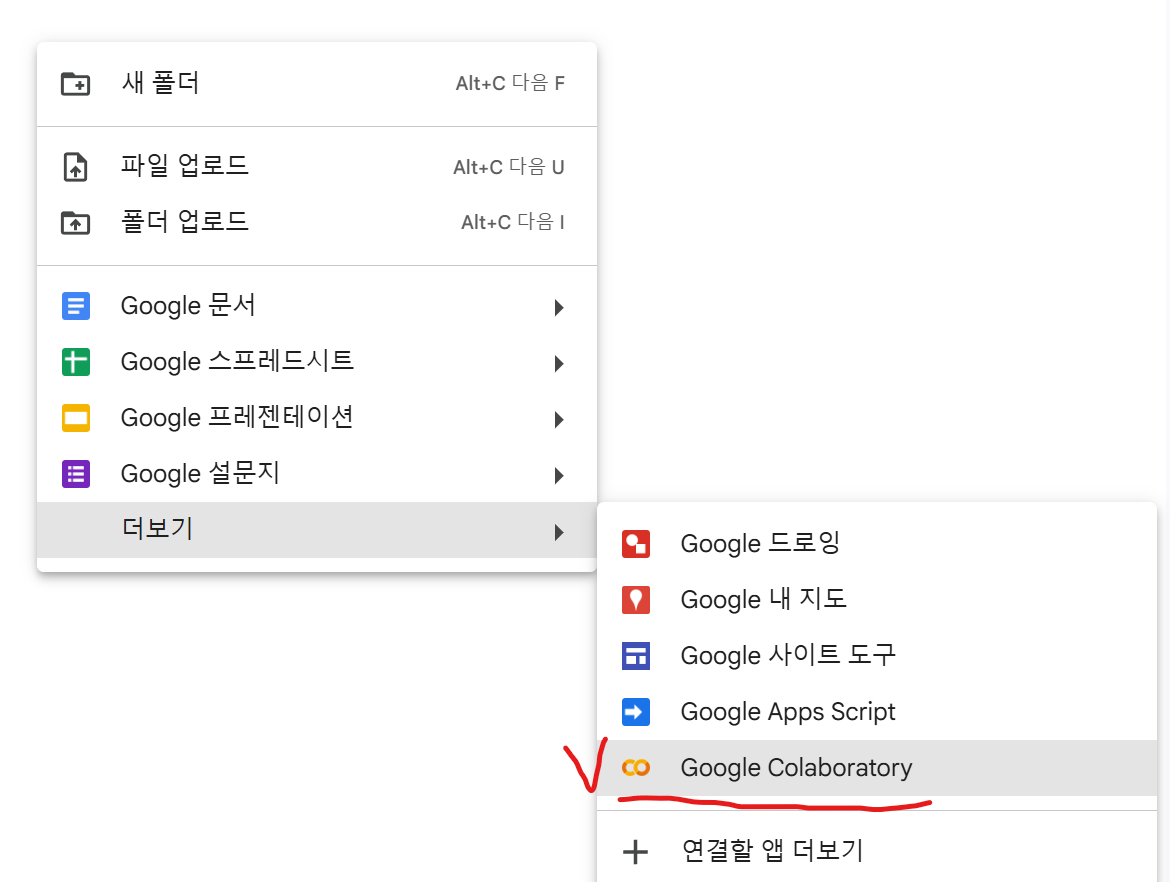
[신규] 버튼을 클릭 → 더보기 → Colaboratory 검색하여 설치
2. 새 노트북 만들기
.ipynb 파일 생성
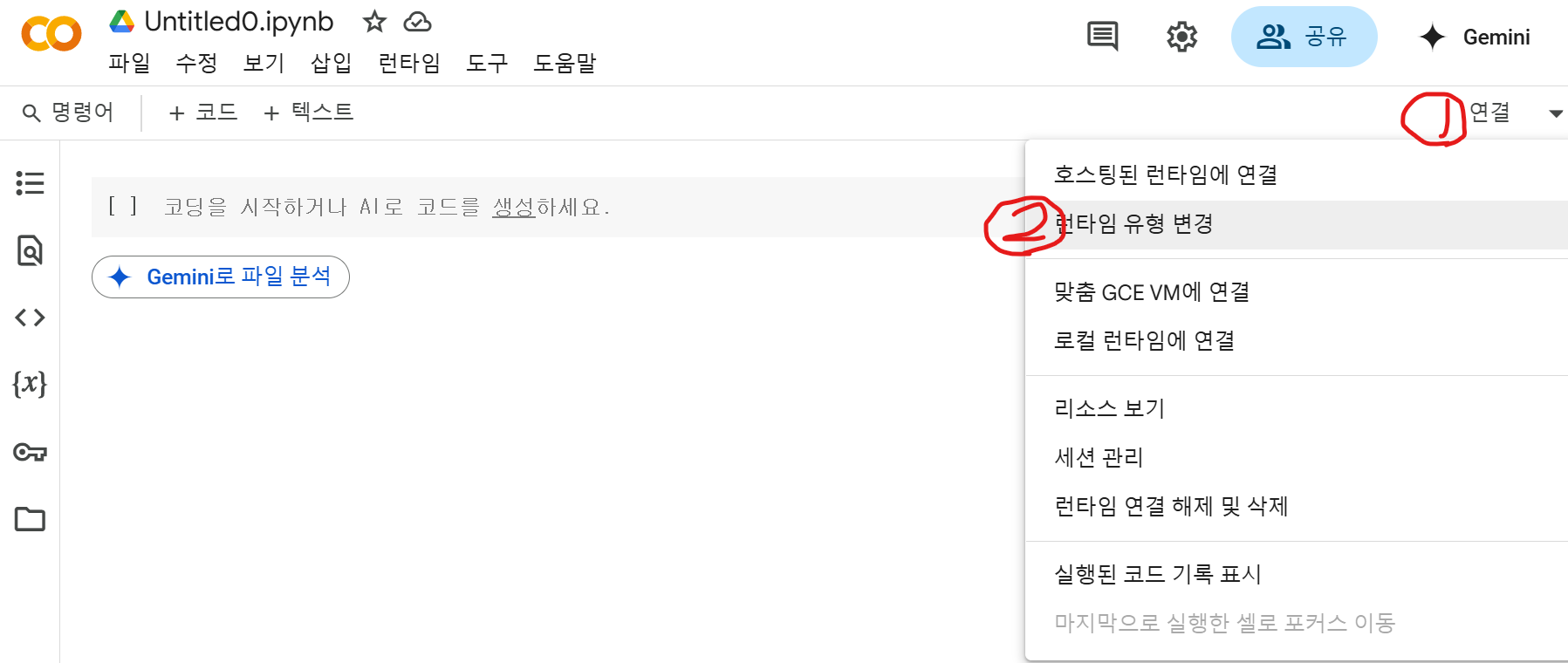
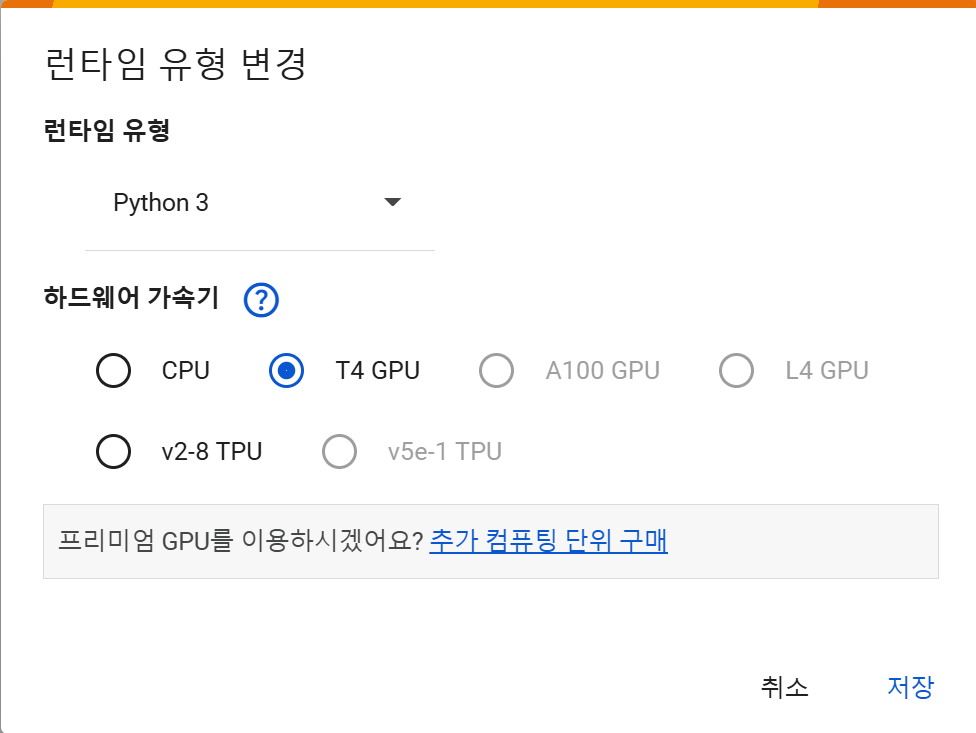
3. 런타임 유형 설정(GPU / TPU 선택)
- 메뉴에서 런타임 > 런타임 유형 변경
- 하드웨어 가속기: GPU 또는 TPU 선택 (기본은 None)
4. Google Drive 연동(파일 저장 및 불러오기)
from google.colab import drive
drive.mount('/content/drive')
→ 처음 한 번은 인증 코드 입력 필요
→ 이후 /content/drive/MyDrive/ 경로를 통해 파일 접근 가능
5. 패키지 설치 및 사용 예시
# pip 명령어 사용 가능
!pip install numpy pandas matplotlib6. PyTorch / TensorFlow 예시 코드
import torch
print(torch.__version__)
print(torch.cuda.is_available()) # GPU 사용 가능 여부import tensorflow as tf
print(tf.__version__)
print(tf.config.list_physical_devices('GPU')) # GPU 확인
📝 추가 팁
- 자동 저장: 모든 작업은 Google Drive에 자동 저장됨
- 유휴 시간 종료 주의: 일정 시간(약 90분) 이상 작업이 없으면 세션이 종료될 수 있음
- 세션 시간 제한: 일반 사용자는 12시간, Pro 사용자는 최대 24시간 가능
7. Colab에서 바로 실행 가능한 딥러닝 예제 코드
주제 : MNIST 숫자 이미지 분류(PyTorch 사용)
# 1. 라이브러리 임포트
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
# 2. 디바이스 설정
# Google Colab에서 GPU 사용 여부 확인(GPU 사용 가능하면 자동으로 CUDA로 설정, 아니면 CPU 사용)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 3. 데이터 전처리 및 로더 설정
# 이미지를 Tensor로 변환하고 픽셀값을 정규화
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# MNIST 데이터셋을 로드하고 DataLoader로 묶어서 배치 처리 가능하도록 함
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False)
# 4. 모델 정의
# 두 개의 합성곱 층(conv1, conv2) --> 풀링 --> 완전연결층 --> 10개 클래스 출력
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 16, 3, padding=1)
self.conv2 = nn.Conv2d(16, 32, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 32 * 7 * 7)
x = F.relu(self.fc1(x))
return self.fc2(x)
model = CNN().to(device)
# 5. 손실 함수 및 최적화 함수
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 6. 학습 루프
for epoch in range(3): # 3 에폭 학습(3회 반복)
running_loss = 0.0
for images, labels in trainloader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"[Epoch {epoch+1}] Loss: {running_loss:.4f}")
# 7. 테스트 정확도 측정
correct = 0
total = 0
model.eval()
with torch.no_grad():
for images, labels in testloader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"테스트 데이터 정확도: {100 * correct / total:.2f}%")
딥러닝 프로젝트나 실험 계획이 있다면 Colab은 최고의 시작 플랫폼입니다.
반응형